Prometheus v2
If you are using Prometheus for monitoring and the popular Grafana stack for dashboarding, you can expose Checkly’s core metrics on a dedicated, secured endpoint.
Activation
Activating this integration is simple.
-
Navigate to the integrations tab on the account screen and click the ‘Create Prometheus endpoint’ button.

-
We directly create an endpoint for you and provide its URL and the required Bearer token.
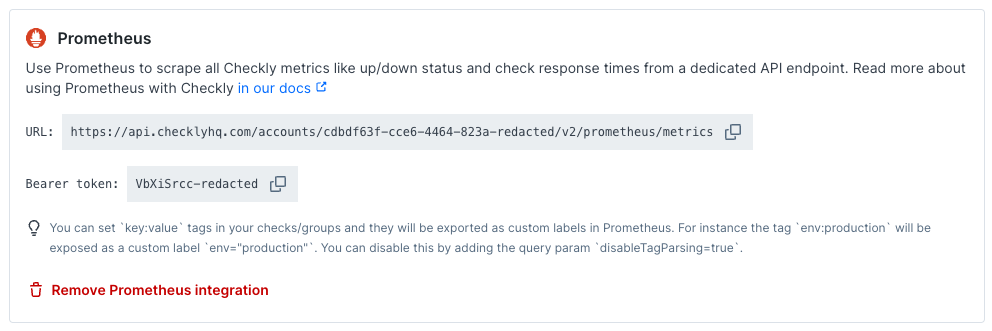
-
Create a new job in your Prometheus
prometheus.ymlconfig and set up a scraping interval. The scrape interval should be above 60 seconds. Add the URL (divided intometrics_path,schemeandtarget) andbearer_token. Here is an example
# prometheus.yml
- job_name: 'checkly'
scrape_interval: 60s
metrics_path: '/accounts/993adb-8ac6-3432-9e80-cb43437bf263/v2/prometheus/metrics'
bearer_token: 'lSAYpOoLtdAa7ajasoNNS234'
scheme: https
static_configs:
- targets: ['api.checklyhq.com']
Now restart Prometheus and you should see metrics coming in.
Check Metrics
The Prometheus exporter exposes several metrics you can use to monitor the status of your checks, as well as to inspect detailed information such as Web Vitals.
The following metrics are available to monitor checks:
| Metric | Type | Description |
|---|---|---|
checkly_check_status |
Gauge | Indicates whether a given check is currently passing, degraded, or failing. |
checkly_check_result_total |
Counter | The number of passing, degraded, and failing check results. |
checkly_browser_check_web_vitals_seconds |
Histogram | The Web Vitals timings. |
checkly_browser_check_duration_seconds |
Histogram | The total check duration. This includes all pages visited and any waits. |
checkly_browser_check_errors |
Histogram | The errors encountered during a full browser session. |
checkly_api_check_timing_seconds |
Histogram | The response time for the API request, as well as the duration of the different phases. |
checkly_multistep_check_duration_seconds |
Histogram | The total check duration. This includes all requests done and any waits. |
checkly_time_to_ssl_expiry_seconds |
Gauge | The amount of time remaining before the SSL certificate of the monitored domain expires. See the SSL certificate expiration docs for more information on monitoring SSL certificates with checks. |
The checkly_check_status and checkly_check_result_total metrics contain a status label with values passing, failing, and degraded.
The checkly_check_status gauge is 1 when the check has the status indicated by the status label and is 0 otherwise.
For example, if a check is passing the result will be:
checkly_check_status{name="Passing Browser Check",status="passing"} 1
checkly_check_status{name="Passing Browser Check",status="failing"} 0
checkly_check_status{name="Passing Browser Check",status="degraded"} 0
checkly_check_status can be useful for viewing the current status of a check, whereas checkly_check_result_total can be useful for calculating overall statistics. For more information see the recipes section.
The metrics checkly_browser_check_web_vitals_seconds, checkly_browser_check_errors, and checkly_api_check_timing_seconds contain a type label.
This label indicates the different Web Vitals, error types, and timing phases being measured.
checkly_time_to_ssl_expiry_seconds contains a domain label giving the domain of the monitored SSL certificate.
In addition, the check metrics all contain the following labels:
| Label | Description |
|---|---|
name |
The name of the check. |
check_id |
The unique UUID of the check. |
check_type |
Either api or browser. |
muted |
Whether the check is muted, configured to not send alerts. |
activated |
Whether the check is activated. Deactivated checks aren’t be run. |
group |
The name of the check group. |
tags |
The tags of the check. |
key:value tags in your checks and groups and they will be exported as custom labels in Prometheus. For instance the tag env:production will be exposed as a custome label env="production". You can disable this by adding the query param disableTagParsing=true.PromQL Examples
This section contains a few PromQL queries that you can use to start working with the Prometheus data.
Currently failing checks
To graph whether checks are passing or failing, use the query:
checkly_check_status{status="passing"}
Passing checks will have the value 1 while failing and degraded checks will have the value 0.
This can be used to build a Grafana table of currently failing checks.
Failure percentage
To calculate the percentage of check runs that failed in the last 24 hours, use:
increase(checkly_check_result_total{status="failing"}[24h]) / ignoring(status) sum without (status) (increase(checkly_check_result_total[24h]))
The checkly_check_result_total counter is reset to 0 every hour. The increase function will handle these resets automatically, though. ignoring(status) is needed so that Prometheus can perform vector matching on the division operation.
Histogram averages
The different histogram metrics can all be used to compute averages. For example, query the average web vitals times for a check using:
sum by(type) (rate(checkly_browser_check_web_vitals_seconds_sum{name="Check Name"}[30m])) / sum by(type) (rate(checkly_browser_check_web_vitals_seconds_count{name="Check Name"}[30m]))
Private Location Metrics
The Prometheus exporter also contains metrics for monitoring Private Locations. These metrics can be used to ensure that your Private Locations have enough Checkly Agent instances running to execute all of your checks.
The following metrics are available to monitor Private Locations:
| Metric | Type | Description |
|---|---|---|
checkly_private_location_queue_size |
Gauge | The number of check runs scheduled to the Private Location and waiting to be executed. A high value indicates that checks are becoming backlogged and that you may need to scale your Checkly Agents. |
checkly_private_location_oldest_scheduled_check_run |
Gauge | The age in seconds of the oldest check run job scheduled to the Private Location queue. A high value indicates that checks are becoming backlogged. |
checkly_private_location_agent_count |
Gauge | The number of agents connected for the Private Location. |
The Private Location metrics all contain the following labels:
| Label | Description |
|---|---|
private_location_name |
the name of the Private Location. |
private_location_slug_name |
the Private Location’s human readable unique identifier. |
private_location_id |
the Private Location’s UUID. |
Last updated on April 26, 2024. You can contribute to this documentation by editing this page on Github